Webpack 5 代码分割完全指南 (Code Splitting)
📚 本指南旨在帮助开发者深入掌握 Webpack 5 的代码分割技术,从基础原理到生产环境的高级配置一应俱全。
目录
- 为什么需要代码分割
- 代码分割的三种方式
- 入口起点分割
- SplitChunksPlugin 详解
- 动态导入(Dynamic Import)
- 魔法注释(Magic Comments)
- 代码分割统一命名规范
- 预获取与预加载
- Tree Shaking 与代码分割的协同
- 实战:完整的代码分割配置方案
- 分析与优化
- 针对不同类型项目的配置建议
一、为什么需要代码分割
在一个未经优化的 Webpack 项目中,所有代码会被打包成 一个巨大的 bundle 文件。这带来几个严重问题:
- 首屏加载慢:用户必须下载全部代码(包括当前页面根本不需要的部分)才能看到页面内容。
- 缓存利用率低:修改任何一行代码,整个 bundle 的 hash 都会变化,用户需要重新下载一切。
- 并行加载受限:浏览器的并发请求能力被浪费,只需下载一个文件却不能利用多连接并行。
代码分割(Code Splitting) 的核心思想就是:把一个大 bundle 拆成多个更小的 chunk,按需加载或并行加载。
1 | ┌──────────────────────────────────────────────┐ |
二、代码分割的三种方式
Webpack 提供了三种方式实现代码分割,它们可以组合使用:
| 方式 | 说明 | 适用场景 |
|---|---|---|
| 入口起点 | 在 entry 中配置多个入口 | 多页面应用(MPA) |
| SplitChunksPlugin | 自动提取公共依赖和第三方库 | 所有项目,尤其是有共享模块时 |
| 动态导入 | 使用 import() 语法按需加载 | 路由级懒加载、大型功能模块 |
三、入口起点分割(不常用)
3.1 基础多入口配置
最简单的代码分割方式是手动在配置中指定多个入口:
1 | // webpack.config.js |
这样会生成 app.xxx.js 和 admin.xxx.js 两个独立的 bundle。
3.2 问题:重复打包
假设 app.js 和 admin.js 都引入了 lodash,那么 lodash 会被 打包两次,分别出现在两个 bundle 中。这显然是一种浪费。
1 | // src/app.js |
打包结果(未去重时):
1 | app.abcd1234.js → 包含 lodash + app 逻辑(约 70KB + 1KB) |
lodash 被重复包含了两次!这就需要 SplitChunksPlugin 来解决了。
3.3 使用 dependOn 共享模块
Webpack 5 提供了 dependOn 选项来手动声明入口间的依赖关系。根据共享模块的数量,有以下几种配置方式:
1)场景一:共享单个模块
1 | module.exports = { |
打包结果(去重后):
1 | shared.xxxx.js → 只包含 lodash(约 70KB) |
2)场景二:共享多个模块
如果入口文件共同依赖了多个第三方库(如 lodash, axios, react 等),你可以通过数组组合或拆分多个共享块来实现。
方案 A:将多个依赖合并为一个公共 Chunk
如果这些依赖体积总和不大,且更新频率相似,可以将它们放在一个数组中:
1 | module.exports = { |
方案 B:将依赖拆分为多个公共 Chunk
如果依赖库职责不同(例如基础 UI 库与工具函数库分开),可以定义多个独立入口,并在 dependOn 中传入数组:
1 | module.exports = { |
3)场景三:共享本地自定义模块
dependOn 的底层逻辑是提取另一个入口 chunk 中的模块,这种“共享”不局限于 node_modules 中的第三方库。你完全可以将自己封装的公用代码(比如一套业务专用的工具函数库、全局状态管理等)提取为一个共享入口。
1 | module.exports = { |
适用情况:
- 你的多个入口应用(如前台和后台)都重度使用了同一个自建组件库或工具集。
- 你希望将这些相对稳定的自建库与频繁变动的业务逻辑拆分,以利用浏览器缓存。
注意与释疑:配置了多个入口(
entry),不代表所有入口都会放在同一个 HTML 页面里。
- 多页应用(MPA)场景:如果是各自独立的 HTML 页面(比如
app.html只引入app.js,admin.html只引入admin.js),此时每个页面只加载一个入口脚本,运行时不会冲突。- 同一页面加载多入口场景:而在本例的
dependOn配置中,shared.js和app.js通常会被同时注入到同一个 HTML 页面中。这种情况下,必须设置optimization.runtimeChunk: 'single',提取出一个公共的 Webpack 运行时(Runtime)。否则shared和app将各自包含一套独立的 Webpack 模块加载与解析逻辑,这会导致全局变量冲突、模块重复实例化等严重的意外问题。- 单页面应用(SPA)适用吗?:不适用,也没有必要。 绝大多数 Vue/React 单页面应用通常只有一个核心入口文件(如
src/main.js或src/index.js)。既然没有“多个”入口,就不存在“跨入口提取共享模块”的需求。对于 SPA:
- 若想抽离第三方库(如
vue,react,lodash),请使用下一节介绍的 SplitChunksPlugin。- 若想实现路由级别的按需加载,请配合使用稍后介绍的动态导入(Dynamic Import)。
1 | module.exports = { |
四、SplitChunksPlugin 详解
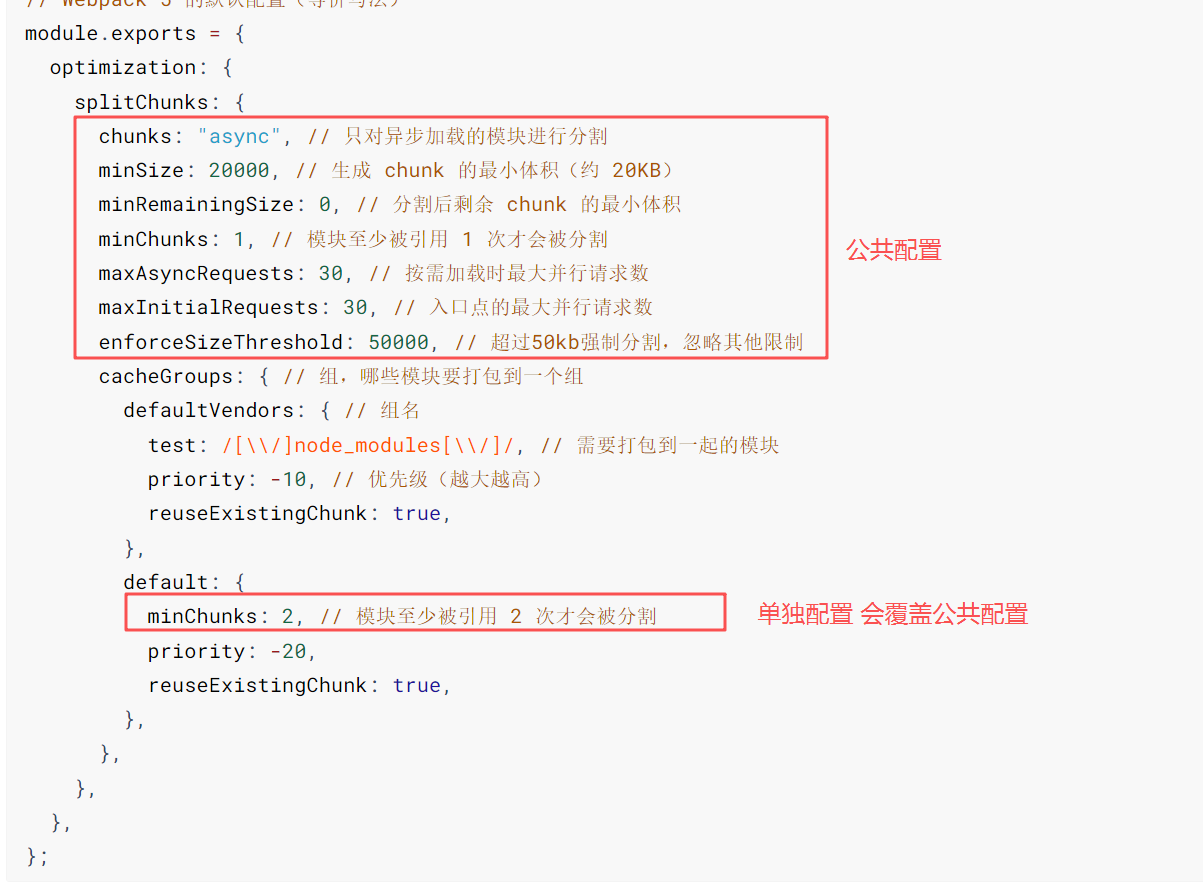
4.1 默认行为
SplitChunksPlugin 是 Webpack 内置的、也是最核心的代码分割工具。它会自动分析模块间的依赖关系,把满足条件的公共模块提取到单独的 chunk 中。
即使你不做任何配置,Webpack 5 也有一套默认的分割策略:
1 | // Webpack 5 的默认配置(等价写法) |
关键点:默认
chunks: 'async'意味着只对动态import()导入的模块生效。如果你也想提取同步引用的第三方库(比如import lodash from 'lodash'),需要改成'all'。
4.2 chunks 选项详解
chunks 是一个非常关键的选项,它决定了哪些 chunk 参与分割优化:
1 | splitChunks: { |
三种模式的区别(以 lodash 为例):
1 | // 场景:入口文件同步引用了 lodash |
| chunks 值 | 效果 |
|---|---|
'async' | lodash 不会被单独提取(因为它是同步引入的) |
'initial' | lodash 会被提取到 vendor chunk |
'all' | lodash 会被提取到 vendor chunk |
1 | // 场景:代码中动态引用了 lodash |
| chunks 值 | 效果 |
|---|---|
'async' | lodash 会被提取为独立 chunk |
'initial' | lodash 不会被提取(因为它是异步引入的) |
'all' | lodash 会被提取为独立 chunk |
chunks 也可以传入一个函数来做更精细的控制:
1 | splitChunks: { |
4.3 cacheGroups 缓存组
cacheGroups(缓存组)是 SplitChunksPlugin 的灵魂。它允许你自定义分组规则,指定哪些模块应该被归入哪个 chunk。
1)匹配流程
1 | 模块被引入 |
2)完整配置示例
1 | optimization: { |
3)cacheGroup 的核心属性
| 属性 | 类型 | 说明 |
|---|---|---|
test | RegExp / Function / String | 模块匹配规则 |
name | String / Function | 生成的 chunk 名称 |
priority | Number | 优先级,数值越大越优先匹配 |
minChunks | Number | 模块最少被多少个 chunk 引用 |
reuseExistingChunk | Boolean | 如果当前 chunk 包含已从 main bundle 中拆分出来的模块,则复用 |
enforce | Boolean | true 时忽略 minSize、maxSize 等限制,强制创建 chunk |
4)深度解析:reuseExistingChunk
reuseExistingChunk: true 这个配置虽然默认开启,但很多人不理解它的具体作用。
它的核心思想是:避免重复打包已经被分离出去的模块。
🤔 场景演示:
假设你有三个文件:A.js, B.js 和一个公共工具模块 utils.js。
A.js引用了utils.js。B.js引用了A.js,同时也直接引用了utils.js。
在配置 SplitChunksPlugin 提取公共模块时:
- Webpack 在处理
A.js时,决定把utils.js提取出来,单独打成一个叫chunk-utils.js的文件。 - 接着 Webpack 处理
B.js。按照依赖分析,B.js需要A.js和utils.js。 - 此时,Webpack 发现
B.js需要的utils.js已经在这个打包流程中被别人(A.js)提取成了一个独立的 Chunk (chunk-utils.js) 了。
如果不开启 reuseExistingChunk: false:
Webpack 可能会比较笨地再为 B.js 把 utils.js 重新打包一次(或者打包进 B.js 内部,或者生成一个新的重复 chunk)。
如果开启 reuseExistingChunk: true(推荐):
Webpack 会很聪明地说:“哦,我已经有一个包含 utils.js 的 Chunk 了,那 B.js 直接去复用那个建立好的 chunk-utils.js 就行了,没必要再单独创建一份。”这样就极大地减小了打包体积,也提高了打包效率。
5)name 的函数用法
name 传入函数可以实现动态命名:
1 | cacheGroups: { |
⚠️ 注意:在生产环境中不建议使用函数形式的
name,因为每个包一个 chunk 会导致 HTTP 请求过多。这里仅作演示。
4.4 体积相关的关键参数
1 | splitChunks: { |
maxSize 的工作方式:
maxSize 并不是一个硬限制(一个 chunk 可能因为无法继续拆分而超过此值),但 Webpack 会 尽量 把超出的 chunk 再次拆分。优先级关系为:
1 | minSize(保底下限)> maxSize(建议上限)> maxInitialRequests/maxAsyncRequests(请求数上限) |
也就是说,Webpack 绝不会因为 maxSize 而创建小于 minSize 的 chunk。
4.5 runtimeChunk 运行时代码提取
Webpack 的 runtime(运行时) 是指模块加载、解析、执行的基础代码。把它提取为单独文件可以避免在业务代码变化时导致 runtime 所在的 chunk hash 变化:
1 | optimization: { |
推荐使用 '方式一和方式三',特别是对于单页面应用。
深度解析:为什么需要提取 runtimeChunk?
🤔 场景演示:
假设你的项目有两个文件:入口文件 main.js 和一个按需加载的 About.js(动态导入)。
如果不提取(默认情况):
- Webpack 会把“模块映射关系”(即 runtime)打包进
main.js。 - 如果你修改了
About.js的内容,About.js的 hash 肯定会变。 - 关键点:由于
main.js内部记录了About.js的新文件名,导致main.js的内容也发生了微小变化,因此main.js的 hash 也会被迫改变。 - 结果:用户本来只需要重新下载最新的
About.js,现在却因为 runtime 的变动,不得不重新下载几百 KB 的main.js(即使业务逻辑没变)。
- Webpack 会把“模块映射关系”(即 runtime)打包进
如果提取(runtimeChunk: ‘single’):
- Webpack 会产生一个微小的
runtime.js(专门存放映射关系)。 - 如果你修改了
About.js,此时只有runtime.js(记录了新映射)和About.js本身的 hash 会变。 - 结果:主逻辑
main.js的内容保持绝对不变,它的 hash 也不会变。这意味着浏览器可以直接从本地缓存读取main.js,大大提升了二次访问速度。
- Webpack 会产生一个微小的
[!TIP]
结论:在追求“长效缓存(Long-term Caching)”的项目中,提取runtime是标配操作。它通过牺牲一次微小的 HTTP 请求(runtime.js通常只有几 KB),换取了大型业务 chunk 的缓存稳定性。
runtime.js 内部到底保存了什么?
简单来说,runtime.js 是 Webpack 在浏览器中的 “总调度指挥部”。它的核心内容通常包括:
- 模块映射表(Manifest):
这是最重要的部分。它记录了所有模块 ID 与其对应的文件 Hash 之间的映射关系。1
2
3
4
5// 伪代码示例:映射表
{
"about": "about.8f2d1a3b.chunk.js",
"home": "home.c5e6d7f8.chunk.js"
} - 核心加载逻辑:
包含 Webpack 的模块加载函数(如__webpack_require__)。它负责管理模块的初始化、缓存以及如何处理模块之间的循环依赖。 - 异步分包加载指令:
提供处理动态import()的底层代码。例如,它包含了如何动态创建<script>标签、如何监听下载进度、以及如何在脚本下载报错时进行处理的逻辑。 - 环境支撑脚本:
如果是开发环境,它还包含了支持 热更新(HMR) 的通信逻辑。
Hash 稳定性的精髓:间接引用
1 | // 伪代码示例:映射表 `runtime.js` |
我们可以用 “查字典” 来类比这个过程:
main.js(读者):它手里拿的是模块 ID(索引)。比如它知道自己需要about这个模块,代码里写的是__webpack_require__.e("about")。runtime.js(字典):它保存了最新的页码映射(映射表)。它告诉读者:“你要找的about,现在在about.8f2d1a3b.js这一页。”
为什么这样就能保护缓存?
- 解耦:
main.js不再直接写死对方带 Hash 的完整文件名,而是通过一个永远不变的 ID(如数字 ID 或具名 ID)去询问runtime.js。 - 局部更新:当你修改了
about.js,它的 Hash 变了(变成8f2d1a3b->9ec2b10a),字典(runtime.js)会更新这一行记录。 - 缓存命中:因为
main.js里的代码__webpack_require__.e("about")一个字都没改,所以它的 Hash 也不会变。浏览器发现main.js没变,就会直接命中磁盘缓存,不需要重新下载!
[!IMPORTANT]
一句话总结:runtime.js充当了 Hash 变动的**“缓冲区”**。它吸收了所有因依赖版本更新而产生的 Hash 波动,从而保护了上层业务逻辑(main.js)的缓存有效性。
五、动态导入(Dynamic Import)
5.1 基础用法
动态导入是实现按需加载的核心手段。使用 ES 标准的 import() 语法, Webpack 会自动将目标模块拆分为独立的 chunk,并在运行时按需加载。
1. 基础用法
1 | // 点击按钮时才加载并使用 lodash |
import('lodash') 做了两件事:
- 在打包阶段,Webpack 会把
lodash及其依赖从主 bundle 中拆分出来,生成一个独立的 chunk 文件。 - 在运行阶段,当代码执行到
import('lodash')时,才会通过<script>标签动态下载并执行这个 chunk。
5.2 路由级懒加载(React)
这是动态导入最常见的实战场景:
1 | import { lazy, Suspense } from "react"; |
5.3 路由级懒加载(Vue)
1 | // router/index.js |
5.4 条件性按需加载
除了路由,还有很多场景适合动态导入:
1 | // 场景一:用户触发了某个功能后才加载对应的库 |
5.5 output.chunkFilename — 非入口 chunk 的命名模板
配合下,Webpack 会产出大量非入口 chunk。output.chunkFilename 就是专门控制这些文件命名格式的配置项,它可以独立使用,不依赖任何魔法注释。
1)filename vs chunkFilename 的分工
1 | output: { |
| 配置项 | 作用对象 | 输出示例 |
|---|---|---|
filename | 入口 chunk(entry 直接对应的) | app.a1b2c3d4.js |
chunkFilename | 非入口 chunk(SplitChunksPlugin 拆的 + 动态 import 的) | vendors.e5f6g7h8.chunk.js |
2)[name] 占位符的值由谁决定?
chunkFilename 模板中最关键的占位符是 [name]。它的值并非固定,而是取决于 chunk 的来源:
| chunk 来源 | [name] 的值 | 文件名示例 |
|---|---|---|
| SplitChunksPlugin 的 cacheGroup | cacheGroup 中配置的 name 属性值 | vendors.abcd1234.chunk.js |
动态 import() + webpackChunkName 注释 | 注释中指定的名称 | about-page.abcd1234.chunk.js |
动态 import() 无任何注释 | Webpack 自动分配的数字 ID | 543.abcd1234.chunk.js |
1 | chunkFilename: '[name].[contenthash:8].chunk.js' |
3)不配置 chunkFilename 会怎样?
如果你不显式设置 chunkFilename,Webpack 会回退到 filename 的值作为所有 chunk 的命名模板。这意味着入口文件和非入口 chunk 使用完全相同的命名规则,虽然功能上没有问题,但你会丧失通过文件名一眼区分”入口文件”和”拆分 chunk”的能力。
推荐做法:给 chunkFilename 加上 .chunk 后缀,方便在构建产物中快速辨认:
1 | output: { |
六、魔法注释(Magic Comments)
Webpack 在 import() 中支持一系列特殊注释(魔法注释),用来精确控制分割行为。
6.1 webpackChunkName — 自定义 chunk 名称
默认情况下,动态 import() 产生的 chunk 会被分配一个纯数字 ID 作为名称(如 543)。通过 webpackChunkName 注释,你可以将其替换为有意义的可读名称,这个名称会填入上一节介绍的 chunkFilename 模板中的 [name] 占位符:
1 | // 不加注释:[name] = 数字 ID → 生成 543.abcd1234.chunk.js |
6.2 webpackMode — 控制动态导入模式
1 | // lazy:默认模式,为每个 import() 调用生成一个可延迟加载的 chunk |
6.3 webpackInclude / webpackExclude — 过滤动态路径
当 import() 的路径包含变量时,Webpack 会把目录下所有可能匹配的文件都打包。用这两个注释可以缩小范围:
1 | // 假设 ./locales/ 目录下有 zh.js, en.js, fr.js, de.js, README.md 等文件 |
6.4 webpackExports — 只导出指定成员
当你只使用模块的部分导出时,这个注释可以帮助 Webpack 做更激进的 Tree Shaking:
1 | // 只使用 lodash-es 的 debounce 和 throttle |
6.5 完整示例:组合使用魔法注释
1 | // 一个路由级懒加载的典型配置 |
七、代码分割统一命名规范
7.1 JS 文件命名
bundle 拆成多个文件。为了在构建产物中一眼区分主文件和分割出来的 chunk 文件,我们需要为 JS 和 CSS 分别制定统一的命名规范。
在 output 中,filename 和 chunkFilename 分别控制入口文件和分割 chunk 的命名:
1 | output: { |
构建产物对比:
1 | dist/js/ |
看到 .chunk.js 后缀就知道这是代码分割产生的文件,没有 .chunk 的就是入口主文件。
7.2 CSS 文件命名
使用 MiniCssExtractPlugin 提取 CSS 时,同样存在 filename 和 chunkFilename 两个配置,逻辑与 JS 完全一致:
1 | const MiniCssExtractPlugin = require("mini-css-extract-plugin"); |
构建产物对比:
1 | dist/css/ |
为什么 CSS 也会被分割?
当你使用动态import()加载一个路由页面时,如果该页面组件中引用了 CSS(例如import './About.css'),MiniCssExtractPlugin会自动将这部分 CSS 也拆分为独立文件,与对应的 JS chunk 配对加载。所以 CSS 也需要chunkFilename来命名这些分割出来的样式文件。
7.3 完整命名规范汇总
| 资源类型 | 配置项 | 作用对象 | 推荐命名模板 | 产出示例 |
|---|---|---|---|---|
| JS | output.filename | 入口文件 | js/[name].[contenthash:8].js | app.a1b2c3d4.js |
| JS | output.chunkFilename | 分割 chunk | js/[name].[contenthash:8].chunk.js | vendors.e5f6g7h8.chunk.js |
| CSS | MiniCssExtractPlugin.filename | 入口样式 | css/[name].[contenthash:8].css | app.a1b2c3d4.css |
| CSS | MiniCssExtractPlugin.chunkFilename | 分割 chunk 样式 | css/[name].[contenthash:8].chunk.css | about-page.e5f6g7h8.chunk.css |
核心原则:所有被代码分割拆出来的文件,统一加上
.chunk后缀,构建产物一目了然。
八、预获取与预加载
我们前面已经做了代码分割,同时会使用 import 动态导入语法来进行代码按需加载(我们也叫懒加载,比如路由懒加载就是这样实现的)。
但是加载速度还不够好,比如:是用户点击按钮时才加载这个资源的,如果资源体积很大,那么用户会感觉到明显卡顿效果。
我们想在浏览器空闲时间,加载后续需要使用的资源。我们就需要用上 Preload 或 Prefetch 技术。
8.1 Prefetch(预获取)
含义:告诉浏览器 “这个资源将来可能会用到,在空闲时提前下载”。
1 | // 当用户在首页时,浏览器会在空闲时提前下载 login-page chunk |
Webpack 会在 HTML 的 <head> 中注入:
1 | <link rel="prefetch" href="login-page.xxxx.chunk.js" /> |
行为特点:
- 浏览器在 空闲时 下载该资源
- 下载优先级 很低,不会影响当前页面的关键资源
- 资源会被缓存,当真正需要时直接从缓存中获取
8.2 Preload(预加载)
含义:告诉浏览器 “这个资源当前页面一定会用到,请立即开始下载”。
1 | // ChartComponent 是当前页面马上就要渲染的内容 |
Webpack 会在 HTML 的 <head> 中注入:
1 | <link rel="preload" as="script" href="chart.xxxx.chunk.js" /> |
行为特点:
- 浏览器 立即 开始下载(与父 chunk 并行)
- 下载优先级 较高
- 如果资源在 3 秒内未被使用,控制台会发出警告
8.3 Prefetch vs Preload 对比
| 特性 | Prefetch | Preload |
|---|---|---|
| 下载时机 | 浏览器空闲时 | 立即并行下载 |
| 优先级 | 低 | 高 |
| 适用场景 | 未来可能需要的资源 | 当前页面即将使用的资源 |
| 与父 chunk 的关系 | 父 chunk 加载完成后才开始 | 与父 chunk 并行下载 |
| 典型应用 | 下一页路由、不常用功能 | 首屏必需的异步模块 |
1 | Prefetch 时间线: |
8.4 实际使用建议
1 | // ✅ 适合 Prefetch 的场景 |
8.5 还需要额外插件吗?(如 @vue/preload-webpack-plugin)
在 Webpack 5 中,不再建议使用 @vue/preload-webpack-plugin 或类似的第三方插件。
- 理由:Webpack 4.6.0+ 已经原生支持了
prefetch和preload魔法注释。当你使用这些注释时,Webpack 会在运行时利用其内置的脚本加载机制,自动在 HTML 的<head>中生成并维护对应的<link>标签。 - 优点:直接使用魔法注释减少了配置复杂度和依赖项。除非你有“全局自动化注入所有异步 Chunk”这种极特殊的批量处理需求,否则魔法注释是目前最标准、最推荐的做法。
九、Tree Shaking 与代码分割的协同
Tree Shaking 和代码分割通常被认为是两个独立的优化方向,但在 Webpack 5 中,它们是深度耦合、互相成就的。
- 代码分割(Code Splitting):解决 “什么时候加载” 的问题。它按文件、按路由将代码拆散。
- Tree Shaking:解决 “加载多少内容” 的问题。它从文件内部剔除没用的导出成员。
9.1 sideEffects:Tree Shaking 的“免检开关”
这是最容易产生误区的地方。sideEffects 的核心作用是告诉 Webpack:若本模块的导出未被使用,是否可以连带其内部的副作用逻辑一并“物理抹除”。
1)深入对比:设置 false vs 不设置
假设有模块 math.js:
1 | // math.js |
| 配置状态 | 场景:import { add } from './math' 但未使用 add | 场景:使用 add |
|---|---|---|
| 未设置 | add 会被剔除,但 console.log 和 window 赋值会保留。Webpack 不敢删执行代码。 | add 保留,副作用逻辑也保留。 |
| sideEffects: false | 整个 math.js 被物理删除。哪怕里面有 console.log 或 window 赋值也统统抹除。 | add 保留,副作用逻辑也保留。 |
[!CAUTION]
风险提示:如果你的代码依赖“只需 import 就能生效”的逻辑(如:CSS、全局变量初始化、Polyfill),必须在package.json中配置数组来排除它们:
9.2 三种导入姿势对 Tree Shaking 的影响
为了配合代码分割和 Tree Shaking 达到最佳体积,导入方式至关重要:
1 | // ❌ 方案 A:全量导入(极其不推荐) |
9.3 当 Tree Shaking 遇到 SplitChunks
这是一个高级协同场景。当你配置了 optimization.splitChunks 时,Tree Shaking 的结果会直接影响公共块的提取。
协同逻辑:
- Webpack 首先对每个入口进行 Tree Shaking 标记(哪些成员没用)。
- 在进行 SplitChunks 公共模块提取时,Webpack 提取的是 “经过 Shake 之后的残余模块”。
- 如果一个公共模块
utils.js在入口 A 里用了a(),在入口 B 里用了b(),那么最后提取出来的commons.chunk.js只会包含a和b的代码。
9.4 结合动态导入与 webpackExports
这是 Webpack 5 提供的极致优化工具。如果你只想动态加载一个巨大模块中的一小部分成员:
1 | // 场景:只想动态加载模块中名为 'specificExport' 的成员 |
底层协同效果:
- Webpack 会为这个特殊的
import()创建一个极小的 Chunk。 - 它会绕过整个
large-library的其他导出成员,利用 Tree Shaking 标记并仅提取specificExport及其必要依赖。
9.5 协同优化检查表
- 项目源码:
package.json里的sideEffects是否已正确设置(包含排除 CSS)。 - 第三方库:是否优先使用了支持 ESM 协议的包(如
lodash-es优于lodash)。 - 导出模式:是否使用了
export default { ... }?(不要这样做,对象形式的默认导出不利于 Tree Shaking,请使用具名export)。 - CSS 处理:是否使用了
MiniCssExtractPlugin?(它能配合代码分割,在 Shake 掉 JS 的同时,也由 Webpack 自动分析并 Shake 掉多余的 CSS)。
十、实战:完整的代码分割配置方案
下面是一个适用于中大型前端项目的生产级代码分割配置:
1 | const path = require("path"); |
产出文件结构预览:
1 | dist/ |
十一、分析与优化
11.1 使用 webpack-bundle-analyzer
安装并配置 webpack-bundle-analyzer,可以直观地看到每个 chunk 的组成和体积:
1 | npm install --save-dev webpack-bundle-analyzer |
1 | const { BundleAnalyzerPlugin } = require("webpack-bundle-analyzer"); |
通过分析报告,你可以发现:
- 哪些包体积过大,需要找替代方案或按需导入
- 哪些包被重复打包到了多个 chunk 中
- 哪些不必要的代码被打包进来了
11.2 使用 stats.json 进行离线分析
1 | # 生成 stats.json |
将 stats.json 上传到以下在线工具进行分析:
11.3 实用的优化检查清单
在完成代码分割配置后,建议逐项检查以下内容:
-
chunks是否设为'all':确保同步和异步模块都能被优化 - 框架核心是否单独分包:React/Vue 版本稳定,应该有独立的长期缓存
- 大型第三方库是否按需导入:如
antd、lodash、echarts不应全量引入 - 路由是否使用了懒加载:除首页外的所有路由页面都应该动态
import() - contenthash 是否被使用:文件名使用
[contenthash]以实现浏览器长期缓存 - runtimeChunk 是否被提取:避免运行时代码嵌入到业务 chunk 中
- 是否配置了 moduleIds: ‘deterministic’:保证未变更模块的 hash 稳定
- prefetch 是否用在了下一步操作:如登录后的首页可以 prefetch
- 是否运行过 bundle analyzer:确认没有意外的大包或重复包
十二、针对不同类型项目的配置建议
在实际的商业项目中,配置通常会根据项目规模(代码量、包数量)在“缓存命中率”和“首屏加载速度”之间做权衡。
12.1 “开发效率型”配置(适用于中小型项目)
这种配置主打“简单、稳定”。它不过度拆分,而是将所有第三方库收纳在一起,减少 HTTP 请求数。
1 | // webpack.config.js |
12.2 “平衡性能型”配置(适用于大多数主流项目)
我们在第十章中提供的配置即为此类型。它的核心逻辑是:
- 核心框架单独分包(如 React/Vue),利用长期缓存。
- 大型 UI 库单独分包(如 AntD/Element),避免阻塞首屏。
- 剩余第三方库收纳到 vendors。
12.3 “极致优化型”配置(针对巨大型项目)
如果你的项目 node_modules 极其臃肿,可以使用 Webpack 5 的 maxSize 配合更激进的拆分。
1 | optimization: { |
12.4 生产级 sideEffects 标准排除清单
这是解决 Tree Shaking 误删问题的标准化 package.json 配置,建议直接作为模板使用:
1 | // package.json |
[!WARNING]
数组配置的“潜规则”:
当你使用数组列出有副作用的文件时,没有出现在清单中的所有其他 JS 文件都会被 Webpack 默认为“绝对纯净”(即sideEffects: false)。这意味着:如果一个 JS 文件不在清单里,即使它内部写了
console.log或修改了全局变量,只要它的export成员未被其他地方使用,Webpack 就会直接跳过并物理删除整个文件,其中的副作用逻辑也会随之消失。建议:
- 养成纯净模块化习惯:JS 文件应只负责导出功能,不应在顶层执行逻辑。
- 如果某些历史遗留文件确实有“只需加载即生效”的代码,请务必将其加入上述清单。
12.5 关于框架的选择
- React 项目:
- 核心:
react,react-dom,react-router-dom必须放在一个priority最高的组。 - 特点:React 自身不提供按需加载,强烈建议配合
React.lazy使用。
- 核心:
- Vue 项目:
- 核心:
vue,vue-router,pinia放在一个组。 - 特点:Vue 的异步组件原生支持良好,建议在
router/index.js中全程使用component: () => import(...)。
- 核心:
结语:没有完美的配置,只有最适合当前项目业务场景的权衡方案。建议每隔一到两个月,运行一次
webpack-bundle-analyzer来巡检你的打包结果。
十三、如何编写 Tree-Shaking 友好的代码(避坑指南)
正如我们在第十二章提到的 sideEffects 机制,如果不规范编码,很容易在项目维护后期掉入“副作用丢失”的陷阱。
1. 致命诱因:混合模块(Hybrid Modules)
这是最典型的维护惨案:在一个文件中既包含了“纯纯的导出成员”,又包含了“加载即执行的副作用”。
1 | // ❌ 极其危险的写法 (utils.js) |
为什么这很危险?
- 假设现在
count函数还在用,项目运行完美。 - 几个月后,同事小张重构代码,发现
count没用了,于是删除了对count的所有引用。 - 如果项目设置了
sideEffects: false且没把utils.js写进例外清单。 - 结局:下次打包线上版时,Webpack 会认为
utils.js没用,直接物理抹除。导致window.globalConfig变成了undefined,线上项目直接白屏。
2. 避坑准则一:物理分离副作用
绝对不要将 utility(工具类)和 initialization(初始化类)逻辑写在一起。
1 | # 推荐的目录结构 |
3. 避坑准则二:拒绝“隐蔽”导入
如果你导入一个文件是为了它的副作用,请在代码中明确体现,而不是指望它“顺便”被加载。
1 | // main.js |
4. 避坑准则三:使用具名导出(Named Exports)
对于对象类型的导出,Tree Shaking 的效果往往不佳。
1 | // ❌ 不利于 Tree Shaking |
总结:Tree Shaking 的最终效果,50% 取决于 Webpack 的配置,另外 50% 取决于你的编码习惯。一个优秀的 Webpack 工程师,必然也是一个深谙“关注点分离”的架构师。